Chapter 4
The listener is the final judge of any audio technology. Listening tests are a necessary stage in the iterative development of any technology that affects the recording and playback of sound. If such tests are not employed, market forces will see to it that the product with audible problems fails.
While listening tests were chosen for this project’s purposes, other methods exist for determining spatial imaging properties. Macpherson [51] implemented a computer model of binaural localization for stereo imaging measurement based on the work of Pocock. This system uses dummy head recordings and a model of human localization to estimate the perceived azimuth of a real or virtual sound. Macpherson’s system was not used for the present application because (1) it is restricted to localizing only frontal sources, (2) no formal listening tests were used to confirm the model’s performance, and (3), implementation is too complex for the scope of this project.
MacCabe and Furlong [25] sought to determine the virtual imaging capabilities of various surround sound systems (i.e., methods of panning) using a simpler localization model. They modeled dummy head ITDs and ILDs resulting from a 30 ms broadband noise burst as either a real or virtual (phantom) source. A loudspeaker was physically moved through each of the test azimuths for the real source test. For the virtual source test, the noise burst was panned with spectral stereo, KEMAR reconstruction (using exact head diffraction measurements), and Ambisonics methods. Their localization model was not used because (1) no comparisons were made between ITDs / ILDs calculated from dummy head recordings versus those from real head recordings, and (2) data was neither given nor referenced relating ITDs / ILDs (calculated from either type of recording) to perceived azimuths.
Others have investigated the image capabilities in just the front sound stage. Crispien and Ehrenberg [52] and Cao et al. [53] have developed models of the cocktail party effect, while Elmar and Leal [6] and Geluk [54] have developed stereo position sensors for use in recording settings. The cocktail party models are too complicated for the purposes of this project, and the stereo sensors are more properly directional sound power sensors than directional hearing models. Without alteration, these methods cannot determine sound source or phantom image locations to the sides and/or rear of the listener.
Very recently, Komiyama [55] and Hoeg and Grunwald [56] developed methods for visually monitoring multichannel stereophonic signals. Their techniques were not assessed or used in this project.
For this project, listening tests were conducted to test for compliance with several of Gerzon’s pan pot and surround sound system design criteria from Chapter 3. Tests were performed in the context of playback over loudspeakers in a domestic five-channel surround sound system. Based on the results of the test (and keeping in mind its limitations), it was hoped that (1) a "best" panning algorithm could be chosen and further optimized, or (2), a new one could be developed that combined best features from more than one pan pot implementation.
Four of the panning algorithms were tested -- constant power, optimal/constant power hybrid, optimal five-channel, and Moorer’s panning matrix optimized for zero 2nd order spatial harmonics. (Linear panning was not tested because it rarely is used in commercial pan pots due to the loudness change when panning between two speakers.) The test was designed to determine whether each algorithm provided a convincing and intended directional effect for the center listening position (pan pot criteria 1 and 6, surround sound criteria 3a), had stable azimuths relative to speaker locations for off-center listening (pan pot criteria 2 and 4), had stable azimuths under head rotation (pan pot criteria 3), was smooth and uniform during moving pans (pan pot criteria 7 and 5), and approximated constant power (i.e., distance) behavior (pan pot criteria 8).
The author is not aware that any listening tests have been performed on either Gerzon’s optimal pan pot or Moorer’s panning matrix. Therefore, results from this experiment should be one of the primary contributions of this project.
This listening test was a pseudo-scientific one with an engineering goal -- to design a "better" surround sound pan pot. Because this test’s purpose was not to examine spatial listening, only applicable and easily implemented procedures from formal localization tests were used. There was no elaborate method of keeping listeners’ heads perfectly motionless and facing forward. The tests were conducted with loudspeakers in only one configuration, as described in the Experimental Set-up section.
As noted previously, the tested algorithms were based only on localization theories in the horizontal plane. The experimenter, rather than subject, made changes to the variable (in this case by playing back differently panned signals from a multichannel recording medium). Table 4.1 shows which theories of spatial hearing are relevant to this experiment, and thus the types of experiments with which it may be compared (based on [14]).
Table 4.1. This listening test according to Blauert’s listening test categories
| Physical phenomena and processes considered | Participating sensory organs | Usual designation | Categorization |
| Interaural differences for air-conducted sound at both eardrums | Hearing (both ears necessary) | Binaural theories for air-conducted sound | Basic (B) Homosensory (Ho) (one sense: hearing) Fixed [Head] Position (F) and Motional [Head Position] (M) |
Listeners were not screened explicitly for hearing acuity or sound localization skills. Blauert notes that symmetric (peripheral) hearing loss as much as 30-40 dB has almost no noticeable effect on localization or on localization blur [14]. While asymmetrical hearing loss does affect localization and increase localization blur, these affected spatial listening abilities become more normal with experience [14]. (Ideally, one would follow the listener selection and training methodologies described in Bech [57] and Toole [58] to ensure the most reproducible results.)
All listeners were college-age music engineering students with music performance skills. A small sample size of eleven listeners was used, and this was thought to be enough to determine the advantages and disadvantages of each algorithm. (The effect of sample size on the results is described in the Results section of this chapter.) All listeners who volunteered were males.
While it was desirable to hide the loudspeakers from each listener’s view, acoustically transparent curtains were neither available nor practical to install in the testing room. Visible loudspeakers may have pulled the auditory event azimuths towards the nearest speaker, but it is thought this would have affected all algorithms equally. An anechoic chamber or other "ideal" acoustic environment was not used because the test room is supposed to represent a domestic living room. This is important because localization differs when room reverberations accompany the sound source (see Chapter 2), and most localization experiments are conducted in anechoic chambers.
The test tape used in the experiment has six sections, with two-minute breaks between each section. In all sections the listener heard short bursts of noise separated by periods of silence. During the periods of silence, listeners wrote down some perceived characteristic of the preceding noise burst. Before they began each of the experiment’s sections, they heard a noise burst three times to reacclimate to it.
The six sections differed by listening position, panning usage, and head position. Table 4.2 describes the six sections. Sections 4-6 are identical to sections 1-3, except the listener was sitting in a different location. In sections 1-3, the listener was sitting in the center listening position with all speakers a uniform distance away. In sections 4-6, the listener was sitting two feet to the right of the center position.
Table 4.2. Listening Test Sections
| Section | Listening Position | Panning Usage | Head Position |
1 | Center | Stationary | Voluntarily Fixed (looking forward) |
2 | Center | Stationary | Motional (free to move) |
3 | Center | Moving | Voluntarily Fixed (looking forward) |
4 | Off-Center | Stationary | Voluntarily Fixed (looking forward) |
5 | Off-Center | Stationary | Motional (free to move) |
6 | Off-Center | Moving | Voluntarily Fixed (looking forward) |
Table 4.3 show which of Gerzon's pan pot criteria were tested as part of this listening test.
Table 4.3. Correspondence between listening test sections and Gerzon's pan pot criteria
Listeners received the following written instructions:
Introduction
This experiment is concerned with your perception of a sound’s location when reproduced over five loudspeakers. The entire experiment should not last more than an hour.
The experiment has six sections, with two-minute breaks between each section. Sections 4-6 are identical to sections 1-3, except you will be sitting in a different location. In each section, you will hear short bursts of noise separated by periods of silence. You should perceive each noise burst as originating at ear level from somewhere around you. The location of each noise burst will be either stationary or moving. During the periods of silence, you will record some perceived characteristic of the preceding noise burst. Before you begin each of the ten experiment sections, you will hear the noise burst three times to reacclimatize yourself to it.
(Listener hears three noise bursts)
Section 1
In this section, you will hear 40 stationary noise bursts. Please keep your head still and facing forward for this section. Do not turn to face the direction of the sound.
As you hear each burst of noise, try to determine the direction of its origination. Record the perceived direction of each sound on the circles on the following pages (see example). Pay attention to the numbering used below, and record your answers in sequence. If you have difficulty because the sound seems to partially surround you (as with a choir), rather than come from a single point (like a single singer), record the direction of the center of the sound as best you can. When you are done writing, look up again and face forward.
Example: If you hear the noise burst a little to the right of center…
you would record your perception like this:
(Two minute break)
(Listener hears three noise bursts)
Section 2
This section is exactly like the preceding section, except that now you may turn your head to face the sound’s direction. Record the perceived direction of each noise burst as before.
(Two minute break)
(Listener hears three noise bursts)
Section 3
In this section, you will hear 16 moving noise bursts. Please keep your head still and facing forward for this section.
Consider the following characteristics of each moving sound:
(Two minute break)
(Listener hears three noise bursts)
Section 4
(Same instructions as Section 1. Listener is now 2 feet off-center.)
(Two minute break)
(Listener hears three noise bursts)
Section 5
(Same instructions as Section 2. Listener is now 2 feet off-center.)
(Two minute break)
(Listener hears three noise bursts)
Section 6
(Same instructions as Section 3. Listener is now 2 feet off-center.)
It was assumed incorrectly that listeners would understand the meaning of "width" in Sections 3 and 6 without giving its definition. Phantom image width therefore was defined verbally to each subject as the sound’s angular width, to be understood as the fraction of the speaker circle taken up by the sound. A gesture showing width to be the size of a pie-shaped wedge completed the explanation.
The rationale for this experimental design is now considered.
Off-center vs. center listening. Off-center listening approximates sitting on a sofa next to someone in the center position. Zacharov [59] studied how off-center seating affected ratings for listener envelopment, low localization blur, and naturalness of presentation for different speakers in a 5.1 home theater. "Generally subjects gave higher mean ratings for the off-axis seating position. This suggests that perhaps subjects prefer to be aware of the surround system [59]."
Recall that Gerzon’s energy vector magnitude, rE, is supposedly relevant to the situation of off-center listening:
The value of rE turns out to provide a good predictor of the degree of image movement as listeners move away from the central listening position … The degree of angular movement of phantom images relative to the apparent speaker directions caused by any given degree of listener movement is proportional to 1-rE [29].
An off-center offset of two feet to the right was chosen for this experiment. This approximates a one person offset and happens to be a third of the distance to the speakers.
The order of randomization for the stationary panned signals can be found in Table 4.4. This should be read one column at a time from top to bottom ("column 1, top to bottom; col. 2, top to bottom; etc."). The panning algorithm abbreviations are CP (Constant Power), M1 (Moorer), Hyb1 (Optimal / Constant Power Hybrid), and Opti1 (Optimal Five-channel). The panning locations are 0, 36, 72, 108, 144, 180, 216, 252, 288, and 324 degrees.
Table 4.4. Randomization of algorithms and azimuths for sections 1, 2, 4, and 5
| CP 0 | Opti1 252 | Hyb1 36 | M1 180 | CP 144 | Opti1 36 | Hyb1 180 | M1 324 | CP 288 | Opti1 180 |
| M1 72 | CP 36 | Opti1 288 | Hyb1 72 | M1 216 | CP 180 | Opti1 72 | Hyb1 216 | M1 0 | CP 324 |
| Hyb1 324 | M1 108 | CP 72 | Opti1 324 | Hyb1 108 | M1 252 | CP 216 | Opti1 108 | Hyb1 252 | M1 36 |
| Opti1 216 | Hyb1 0 | M1 144 | CP 108 | Opti1 0 | Hyb1 144 | M1 288 | CP 252 | Opti1 144 | Hyb1 288 |
Each perceived azimuth recorded by the listeners was measured on an interval scale of measurement as an angle from 0º to 360º. (Other potential scales are nominal, ordinal, and ratio scales.) Interval scales have an arbitrary reference or starting point, equally spaced ticks, and inherent order or ranking. They are linear and cannot be used proportionally (100° is not "twice" 50° ). For the entire experiment, the reference point of 0° azimuth is straight ahead (towards the Center speaker for sections where the listener is in the center position).
Surprisingly, different results may have been produced if the listener simply pointed in the direction of the perceived auditory event and the experimenter recorded the answers. Blauert describes this phenomenon:
The pointer method is, however, insufficient to assign the position of a sound source to that of an auditory event. The direction of an auditory event cannot be determined from what the subject indicates by pointing unless the relationship between the physically measurable direction of the pointer and the direction of the perceptual event corresponding to the pointer is known. This important consideration is often not taken clearly into account [14].
He notes that one acceptable method of measurement is to ask the subject to make an interval judgment for the direction of a given auditory event and say or write it [14]. This written method was chosen for the present experiment.
Moving panning. For the moving pan sections (3 and 6), the sound was moved around the listener in arcs of 90°. Figure 4.1 shows how the sound was panned through each quadrant of the circle either clockwise or counter-clockwise. Each sound panned thus was randomized among the four algorithms.

Fig. 4.1. Ninety-degree moving pan regions for sections 3 and 6.
The panning trajectories are counter-clockwise 0º to 89º (Region 1), clockwise 179º to 90º (Region 2), clockwise 269º to 180º (Region 3), and counter-clockwise 270º to 359º (Region 4). In each case, the relevant pan pot was "turned" at an arbitrary, uniform rate of about 64.3 degrees/second. The order of randomization for the moving pan tests can be found in Table 4.5, which can be read similarly to Table 4.4.
Table 4.5. Randomization of algorithms and moving pan regions for sections 3 and 6
| CP 0 -> 89 | Opti1 0 -> 89 | Hyb1 270 -> 359 | M1 179 -> 90 |
| M1 269 -> 180 | CP 179 -> 90 | Opti1 179 -> 90 | Hyb1 0 -> 89 |
| Hyb1 179 -> 90 | M1 270 -> 359 | CP 269 -> 180 | Opti1 269 -> 180 |
| Opti1 270 -> 359 | Hyb1 269 -> 180 | M1 0 -> 89 | CP 270 -> 359 |
It is unclear how the speed of the moving pans may affect results. Some insight may be gained from Blauert’s [14] and Moorer’s [11] comments on the perception of moving sound sources. Blauert refers to Aschoff [60] in which a noise signal was constantly switched between eighteen loudspeakers arranged in a circle around the listener. (This was hard switching, not the smooth panning from any continuous panning law.) When the switching speed was slow (Blauert gives no specific rates), subjects heard the noise circling their heads as expected. When the speed was increased, the noise was perceived to oscillate between the left and right sides of the subjects’ heads. As the speed was increased further, a "diffusely spatially located, spatially constant auditory event" was heard approximately in the middle of the head.
Moorer, seemingly referring to all panning laws, states that a limit exists on the speed of such moving pans. If the rate is too high, "it starts to be perceived as being amplitude-modulated rather than simply placed in space." (Moorer also gives no specific rates.) He says that the sidebands produced by the rapidly changing panning functions are audible. Although it was not done for this experiment, it would be useful to try to reproduce Aschoff’s and Moorer’s results and determine the moving pan speeds at which the auditory event is perceived to change in character.
While it would be interesting to have listeners sketch a picture of the sound’s perceived trajectory, applying statistical methods to the results would be difficult or impossible. Instead, the listener answered three questions relating to the speed, distance, and image width of each moving sound. (See the listener questionnaire text above.) These three questions employed a ratio scale of measurement. Ratio scales are characterized as follows: nonlinear, having all the properties of interval scales but with an inherent (rather than arbitrary) reference point, and having all values in ratio with another value. The inherent reference point here corresponds to when each spatial characteristic is fully consistent throughout the sound’s motion. This is represented with a score of 10. A score of 5 would mean that the spatial characteristic was half that of a perfectly consistent moving pan.
Head position. Head position was a variable because localization blur decreases if listeners are free to move their heads. (See Chapter 2, Motional theories.) For sections 1, 3, 4, and 6, listeners were asked to keep their heads still and looking forward to listen to each panned noise burst. In real home theaters, listeners typically will be facing forward when (1) they are watching television screens, or (2) listening to a surround sound system.
Recall also that Gerzon’s velocity vector magnitude, rV, "describes the degree of phantom image movement according to interaural phase localization theories as the listener’s head is rotated; if rV <1, the apparent image rotates in the same direction as the head [desired], whereas if rV >1, the apparent image rotates in the opposite direction [undesired] [28]." If we are to accept this, the algorithms whose value of rV exceeds unity for a large percentage of the 360º circle should show worse performance in the sections where head movement is allowed.
Signal Selection and Presentation
Humans localize different sounds in different ways, so the choice of signal used in localization tests is important. Signals used in past localization studies include impulses, sinusoids, sinusoids with Gaussian envelopes, broadband noise, narrow-band noise, and speech. Localization blur varies between 0.9º and 11.8º among these signals for the forward direction [14]. (Localization blur for speech tended to be the lowest of all signals, as one would expect.) "At right angles to the direction in which the subject is facing, the localization blur attains between three and ten times its value for the forward direction ... Behind the subject the localization blur decreases once more, to approximately twice its value for the forward direction [14]."
A white noise signal filtered to simulate the power spectral density of music was selected for this test [14] because pan pots typically are applied to musical instrument or speech signals. Blauert references work by Skudrzyk (1954) who measured typical PSDs for music and speech and found that music’s PSD wholly included that of speech. Because musical styles and recording techniques have changed since Skudrzyk’s study, the author chose to use a more updated approximation of music’s typical spectrum. Compact disc recordings were selected from six different genres of music: classical, country, 80’s synthesizer pop, jazz, heavy metal, and vocal. Table 4.6 lists these recordings. A ten-second sample from a louder section of each recording was chosen and re-recorded into a computer as a mono, 44.1 kHz, 16-bit WAV file. These transfers were made through a D/A and A/D converter in the CD player and computer’s sound card.
Table 4.6. Recordings used for average music spectrum
Genre | Recording |
| Classical | Beethoven 5th Symphony, Allegro con brio, from the Enjoyment of Music series, Vol. I, CD 4 |
| Country | Marty Stuart "Honky Tonkin’s What I Do Best," from the album of the same name |
| 80’s Synth Pop | Duran Duran "Hungry Like the Wolf," from "Decade" |
| Jazz | Miles Davis and his Orchestra "Boplicity," from the Smithsonian Collection of Classic Jazz, revised, Vol. IV |
| Heavy Metal | Van Halen "Panama" from "Van Halen: Best Of, Volume I" |
| Vocal | The Sarafina Band "The Lord’s Prayer" (a vocal only section) from the "Sarafina" soundtrack |
The resulting WAV files were analyzed and processed using Matlab. Each file first was truncated to 440,000 samples (just under 10 seconds long) and normalized for unit energy and zero mean. Eq. (4.1) shows the unit energy normalization equation, where si(n) is the sequence of samples in the i-th digital audio file, indexed by n.
(4.1)
The DFT was taken of each of the normalized sequences, si_norm(n), producing Si(m) (Eq. (4.2)), where m is the frequency bin and N = 44.1 samples/s * 10 s = 441000 samples.
(4.2)
To reduce the subsequent number of computations, each Si(m) was decimated in frequency by a factor of M = 7. (The choice of the decimation factor is explained below.)
(4.3)
A simple arithmetic average was made of all six complex spectra, producing the average ("typical") music spectrum A(k) in Figure 4.2.
, where i = 6,
(4.4)

Fig. 4.2. Average music spectrum A(k).
This average spectrum was cepstrally smoothed using a method from Rabiner and Schafer [60]. "This type of filtering is appropriately termed ‘frequency invariant linear filtering [60].’" The cepstrum cp(n), defined as the IDFT of the log spectrum, is first computed. Eq. (4.5) describes this calculation, and Figure 4.3 graphically shows the results.
,
(4.5)
where N = ceil(441000/7)= 63000 samples. (Here we actually describe the approximate cepstrum cp(n), which uses the IDFT, rather the true cepstrum c(n) which relies on the inverse Fourier transform.)

Fig. 4.3. Sections of the approximate cepstrum, cp(n), for a speech signal.
The "low-time" section of the cepstrum describes the smoothed component of our average spectrum. This smoothed component can be selected by applying a rectangular window hlow(n) to the low-time portion of the cepstrum, in effect lowpass filtering the spectrum A(k). A window size of 0.05 * N was found experimentally to yield the best smoothing of A(k). Eq. (4.6) describes the windowing process:
(4.6)
Finally, the inverse cepstrum was computed using the DFT:
,
(4.7)
producing a smoothed version of the original spectrum, Asmooth(k), shown in Figure 4.4.

Fig. 4.4. Cepstrally smoothed average music spectrum, Asmooth(k).
A white noise signal then was generated in Matlab with zero mean and unit energy. This was filtered in the frequency domain by simply multiplying it by Asmooth(k). By applying the IFFT, we obtained noise filtered to simulate music as originally desired. The magnitude spectrum of this filtered white noise should appear as in Figure 4.4.
Other choices to be made in the selection of a signal are its time duration and amplitude envelope. Blauert noted that several researchers hypothesized that signal durations of at least 700 ms lead to decreases in localization blur [14]. Thus the duration of the filtered noise bursts was chosen to be at least 700 ms in case these localization blur theories are correct. A rectangular envelope was chosen arbitrarily for the noise bursts.
A 700 ms duration was used in all test sections where the filtered noise burst was panned at a stationary azimuth (sections 1, 2, 4, and 5). Because listeners would need more time to characterize the noise bursts in the sections with the moving pans, a 1.4 second duration was used in sections 3 and 6. Frequency spectra from the original music selections were decimated by a factor of 7 to ensure a signal duration of just over 1.4 seconds. The final filtered noise signal was truncated exactly to produce both the long (1.4 second) and short (0.7 second) monophonic signals at a 44.1 kHz sampling rate.
Discussion is also necessary concerning the need for familiarity with the signal, the duration of silence between noise bursts (allowing listeners time to write down their perceptions), and the duration of breaks between sections. Blauert sums up all the relevant theory. Based on a study by Plenge and Brunschen [63], he states that familiarity with the signal plays a role in directional hearing in the median (rather than horizontal) plane [14]. Plenge and Brunschen found that brief signals having impulse content were consistently localized to the rear of the actual location. "When these signals have been presented to the subject for a short time before the actual experiment, this effect does not occur [14]."
Familiarity also plays an important role in the perception of spatial distance, especially with speech signals in the rear [14]. While the present experiment is concerned with localization in the horizontal plane, it nonetheless was designed to provide the listener with some familiarity with the signal. Before each section, the listener hears three noise bursts played through all five speakers.
Blauert continues as follows:
If the auditory system is stimulated for a relatively long period of time, its sensitivity decreases by a certain amount that depends on the type, level, and length of presentation of the signal. The decrease is due to adaptation and fatigue. ‘Adaptation’ refers to the relatively rapid loss in sensitivity that begins after a few seconds and attains its maximum after approximately 3-5 minutes. Readaptation (i.e., a return to the original sensitivity) takes 1-2 minutes. ‘Fatigue’ occurs with signals of higher intensity and longer duration, and the return to normal sensitivity requires a longer rest period. The transition between adaptation and fatigue cannot be easily defined psychoacoustically, although the two phenomena are clearly different from a physiological point of view [14].
Blauert summarizes by saying "adaptation and learning are observed in studies of directional hearing in the median plane and particularly in studies of distance hearing [14]."
The duration of silence between noise bursts was chosen to be 3.3 seconds for the 0.7 second signals, and 4.6 seconds for the 1.4 second signals (allowing for easy time calculations). This was a compromise between longer times (to decrease adaptation and allow more time for writing answers) and shorter times (to shorten the duration of the entire experiment). The duration of silence between sections was chosen to be 2 minutes to allow for readaptation. The Observations part of this chapter describes how well these time durations worked in practice.
Matlab was used to prepare the noise burst signals for subsequent arrangement. Matlab was programmed to produce three groups of mono, 16-bit WAV files, each with five files corresponding to the five speaker channels. Group 1 contained three noise bursts in sequence at equal volume in all five channels. This was played before each test section to familiarize the listener with the signal. If we include the silences between each noise burst, Group 1 is 3 x 4 s = 12 s in duration. Group 2 contained the noise bursts panned to stationary azimuths. Since there were four panning algorithms and ten azimuths, there were forty randomized noise bursts in this group. Group 2 is 40 x 4 s = 160 s in duration. Group 3 contained the 90º moving pans of the noise bursts. Since there were four algorithms and four moving pan regions, there were sixteen randomized noise bursts in this group. Group 3 is thus 16 x 6 s = 96 s in duration.
The resulting groups of WAV files were arranged using Deck 2.6 multichannel audio editing software for the Macintosh. The method of arrangement is shown in Table 4.7. Ten seconds of silence were placed between each group. Note than an error made in the editing of Group 3 in Deck is described in the Observations section.
Table 4.7. Listening Test Sections and Recording Groups
| Section | Listening Position | Panning Usage | Head Position | Arrangement of Recording Groups |
1 | Center | Stationary | Voluntarily held looking forward | Group 1, Group 2 |
2 | Center | Stationary | Able to move | Group 1, Group 2 |
3 | Center | Moving | Voluntarily held looking forward | Group 1, Group 3 |
4 | Off-Center | Stationary | Voluntarily held looking forward | Group 1, Group 2 |
5 | Off-Center | Stationary | Able to move | Group 1, Group 2 |
6 | Off-Center | Moving | Voluntarily held looking forward | Group 1, Group 3 |
Finally, all five channels of the composite playlist in Deck were transferred simultaneously from the Macintosh to an Alesis ADAT-XT using a Korg 1212I/O digital audio card. The transfers were made in the digital domain to an ADAT tape at 44.1 kHz. The channel/speaker assignments are shown in Table 4.8.
Table 4.8. Correspondence of Loudspeaker and Channel Number
| Loudspeaker | Channel Number |
| Right (R) | 1 |
| Center (C) | 2 |
| Left (L) | 3 |
| Surround Left (SL) | 4 |
| Surround Right (SR) | 5 |
Equipment. The following equipment was used during the listening test.
Loudspeaker placement. Loudspeaker placement relative to the listener and room affects listener preferences and obviously affects localization. Placement of speakers for a surround sound system is more complicated and more critical than that for a traditional stereo system. Loudspeaker placement can be categorized into azimuth, elevation, and distance. (Room related effects were ignored for the most part.) In general, the author was aware of many of the effects of loudspeaker placement but was not able to control all of them due to time and room constraints.
Two sets of recommendations for speaker azimuths were consulted for this test, those from Dolby [64] and Badger and Davis [65]. Dolby recommends placing the L and R speakers 22.5 degrees out from the C speaker, thus making a 45° angle between the L and R speakers. Dolby also recommends that the SL and SR speakers be directly to the left and right of the listener’s head [64]. Figure 4.5 (a) shows this configuration.
Badger and Davis recommend the following:
Earlier stereo literature suggests that an angle of 60 degrees for the angle subtended by the front speaker is optimal for stable imaging. In surround reproduction, further considerations are in order due to the many types of images formed: (1) single speaker sources, (2) left-right phantoms, (3) front-back phantoms, (4) diagonal splits, and (5) elevated and depressed images… It does appear however that side and rear imaging can be improved by locating the rear speakers in an arc of 120 behind the listener in a four speaker array [65].
Figure 4.5 (c) shows this configuration.
The frontal angles from the Dolby recommendation and the rear angles from Badger and Davis’ recommendation were used in this project. This configuration is equivalently a Dolby recommended layout modified for better rear localization. Figure 4.5 (d) shows this compromise speaker configuration.

Fig. 4.5. Azimuths of five speaker set-ups: (a) Dolby Pro Logic/Digital, (b) the author’s misinterpretation of Dolby’s recommendation,
(c) Badger and Davis, (d) Hybrid system used for this experiment.
Unfortunately, this author misread the Dolby recommended speaker set-up as that shown in Figure 4.5 (b). The 45° angle between the L and R speakers was read as 45° between the L and C speakers, and another 45° between the C and R speakers -- double the actual recommended width. (Recall that the choice of speaker angle not only affects physical speaker placement but also the computation of all panning algorithms. The speaker set-up in Figure 4.5 (d) was used in all multichannel panning plots in Chapter 3.) The results of the test are expected to be less relevant for systems with main speakers subtending such a smaller angle (45° ).
Loudspeaker azimuths for all configurations are shown in Table 4.9. In this table, all speakers are understood to point directly towards the center of the speaker circle.
Table 4.9. Recommended and tested azimuths for 5 speaker set-ups
| Loudspeaker | Dolby Pro
Logic/ Dolby Digital | Misinterpretation of Dolby recommendations | Badger and Davis | Hybrid system used in this experiment |
| Right (R) | 337.5° | 315° | 330° | 315° |
| Center (C) | 0° | 0° | 0° | 0° |
| Left (L) | 22.5° | 45° | 30° | 45° |
| Surround Left (SL) | 90° | 90° | 120° | 120° |
| Surround Right (SR) | 270° | 270° | 240° | 240° |
The use of video monitors in home theater systems affects speaker placement just as it affects sound localization. (See the section on visual considerations below.) For descriptions of how video monitors affect loudspeaker placement, the interested reader should consult [61], [63], [64] and [65].
Rodgers [19] shows that loudspeaker height is "critical for preventing the generation of unwanted image elevation and localization errors," even in horizontal-only surround sound systems. She recommends loudspeakers at elevation angles in the range between 12° to 15° . Higher elevation angles supposedly cause image displacement.
The Dolby recommended heights are: front speaker tweeters at ear level, surround speaker tweeters 2 feet above ear level. This recommendation seems to be a holdover from the Pro Logic days of mono surrounds and is probably based on creating an ambient, diffuse sound field. Because of the room used in this test, the loudspeaker tweeters were forced to be at ear level (within about 4 inches). Tweeter location recommendations are necessary for good imaging because the ILD methods used in current pan pots are most effective above about 1.6 kHz. (See Chapter 2 and Chapter 3, Rationale for IID-based Panning.)
Loudspeaker distance obviously affects the ILDs and ITDs of listeners. Badger and Davis note that "under no circumstances should the signals from the rear speakers arrive at the listener before the corresponding signals from the front [65]." The obvious constraint on loudspeaker distance is that all speakers be at a uniform distance from a listener in the center listening position. Dolby makes no recommendations about (uniform) speaker distance, presumably acknowledging that they may not be practical in a typical home. Note that most audio-video receivers let the user set delay times for each channel to account for different speaker distances.
Several things are affected by loudspeaker distance. Importantly, the time and amplitude of room reverberation relative to the direct sound are affected by speaker distance (and placement in general). In Chapter 2, we discussed room-related effects on localization of real sound sources. Now we are concerned with how speaker placement affects interaction of the virtual sound source with the room.
Gerzon found that loudspeakers placed more than 1-1/2 m from the nearest wall lead to an echo threshold of about 10 ms for typical signals [40]. (Recall that the echo threshold is the time between two auditory events after which they are localized separately.) He found that an auditory event was perceived at more than one location as the speakers were moved farther away from the room’s walls. Therefore, Gerzon preferred a speaker distance of 1-1/2 m from the nearest wall.
Griesinger studied localization of phantom images between two loudspeakers as a function of frequency in small rooms [2]. Neither the number of subjects nor a statistical interpretation of his results is given. He examined localization of two speech signals band-limited to 180 - 400 Hz and 1.5 - 2 kHz respectively. These were reproduced over a variety of speaker pair positions placed symmetrically in both semi-free-field conditions and three rooms. Localization and localization blur were found to be highly dependent on the room and loudspeaker configurations. For the low frequencies, small rooms were found to pull phantom images towards the center of the room between the speakers (compared to the same loudspeakers in the free field). For high frequencies, images were more widely separated away from the center but often were "smeared." If this smearing may be interpreted as higher localization blur, then it is certainly an undesirable effect.
In this listening test, room constraints forced the loudspeaker distance to be 6 ft (~1.83 m) from the center listening position and between 3 and 7 ft from the nearest wall. Gerzon notes that the restriction of plane wave behavior (at 2 to 3 m from a sound radiator) is not fundamental to his theories of localization but merely simplifies their derivation [40]. No specific problems with this arrangement were expected. Figures 4.6 and 4.7 show the speaker arrangement and listening test room (a studio control room). Note that the five speakers were oriented such that the listener was facing the back of the control room. The mixing console and the effects rack provided convenient speaker stands in this backwards orientation.
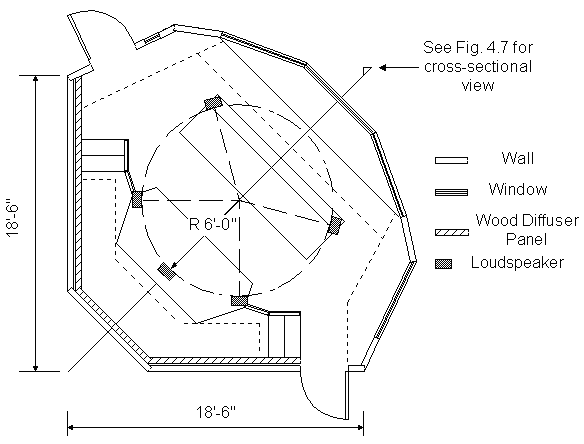
Fig. 4.6. Overhead view of listening test room with loudspeaker circle superimposed.

Fig. 4.7. Cross-sectional view of listening test room with listener head shown.
For more information on the effects of loudspeaker placement, the reader should consult the article by Olive et at. [69].
Loudspeaker selection. The ideal and actual types of loudspeakers are now be described. Full-range speakers are necessary due to the filtered noise signal’s relatively wide spectrum, as shown in Figure 4.4. The directionality of the speakers is relevant to sound localization directly and indirectly through the effects of room reverberations.
Holman [66] states that high directionality is preferable for cases where ease in locating discrete sources is desirable. Wider directivity (low directionality) speakers led to a greater feeling of envelopment. Here he describes the results of double-blind test on an unknown number of listeners in a room measuring 25 x 35 x 12 ft:
The results were unequivocal to the subjects: the narrower directivity loudspeaker produced greater "clarity" of dialog and better localization of individual sounds in a complex stereo sound field despite competition from many other effects … These were surprising results, since reverberation time, discrete reflections and background noise were all negligible. If any of these had been a factor, the result would probably have favored the narrow-directivity system even more [66].
He summarized his personal experience and experimental findings as follows. "Strong sound imaging is promoted with narrow-directivity speakers, and this technique extends to supporting picture images with sound image [66]." Zacharov [59] also found that narrow directivity speakers yielded easier localization both on- and off-axis. He attributed this property to their lower excitation of room reverberations.
In this test, five NHT SuperOne loudspeakers were used. NHT does not publish the directionality pattern of the SuperOnes. The SuperOnes are reported to have a frequency response of 57Hz - 25KHz ± 3dB. The lower cutoff of the frequency response was not thought to be a problem for this test. ITD cues in this lower frequency range would be lost but this should not affect the operation of our IID-based panning laws.
System distortion. Blauert notes that harmonics produced by distortion in the signal chain can produce auditory events at different locations [14]. Care was taken to avoid digital clipping during all phases of source signal generation, panning, arrangement, and eventual transfer to ADAT tape. (To this end, the noise bursts had to be attenuated in Matlab to maximum values of 0.9 to avoid clipping during its wavwrite operation.) The Alesis ADAT-XT, Denon receiver, and NHT SuperOnes were assumed to have distortion low enough for the purposes of this test.
Loudness. Loudness is relevant to the listening tests in two ways. Controlling overall system loudness and calibrating all speaker channels for equal loudness are both important. System loudness affects the perception of both sound quality and stereo imaging [70]. Blauert quotes several studies that found that lateralization blur decreases between low and intermediate sound levels, and then "remains constant or increases slightly as the level continues to rise [14]." Differences in loudness between the speakers in a surround sound system will directly affect localization of phantom sources because the panning algorithms themselves are based on achieving level differences between the two ears.
Different objective measures of loudness correspond to subjective measures at different sound levels. A-, B-, C-, and D-weighting of sound level measurements are used to approximate subjective perceptions of relative loudness for increasing sound levels. (ISO 532 methods may be used for absolute loudness measurements.) For pink noise stimuli, Aarts [70] found that B-weighted loudness measurements best corresponded to subjective measurements for a sound level at 80 phons, which is supposedly typical for listening tests with loudspeakers. ISO 532B and C-weighted measurements were the next best measurements at this sound level. Bech [71] studied the subjective loudness calibration of four channel surround sound systems, and found that the sound stimuli used for the test had a significant influence on the calibration. Specifically, "an objective calibration based on B-weighted pink noise adjusted for equal SPL (Lin.) for the individual channels measured at the listening position corresponded to a subjective calibration using a B-weighted pink noise signal [67]."
Time constraints on listening test development made the creation of B-weighted noise bursts impractical for system and channel loudness calibration. For the overall system loudness calibration, one of the 0.7 s, music-filtered noise bursts over all channels was used as the stimulus. Total system loudness was measured at 75 dB C (slow or fast) with the level meter at ear level and pointed toward the center speaker. (Measurements were made using a Radio Shack digital sound level meter, which was limited to A- and C-weighting curves.) System loudness did not exceed this value for the entire test.
For the speaker relative loudness calibrations, the Denon receiver provided an assumed pink noise stimulus and a built-in calibration procedure that allowed for channel gain adjustments in 1 dB increments. Speaker channel calibrations were made relative to the center channel at 70 dB C (slow) with the level meter pointed at the speaker being calibrated. (Speaker channel delays were not necessary because all speakers were positioned 6 ft from the center listening position.)
Visual considerations. Visual considerations are surprisingly relevant to sound localization. Shelton and Searle [72] investigated the effects of vision on localization using sighted and unsighted subjects. They found that vision improved localization accuracy on the horizontal plane and that the exact effect depended on the orientation of the loudspeakers relative to the head.
After determining that a curtain could not be used to hide the loudspeakers, the author had planned on blindfolding listeners. However, Woszczyk et al. [73] report that voluntary eye movements are used to update the sound position memory. Subjects who were allowed to move their eyes towards the sound source exhibited increased localization accuracy. Because freedom of eye movement was desired, blindfolding was not used. Instead, the lights in the test room were dimmed as much as possible while still allowing listeners to read and write upon their questionnaires. Unfortunately, the specific lighting conditions will be difficult to reproduce if one wants to repeat the experiment.
Visual effects are especially important in systems incorporating video screens in addition to a surround sound system. Woszczyk et al. [73] reference Iwamiya and Teshima [74], who found that the size of a video display affects the localization of sound. They noted that an "optimum balance of [video and audio] intensities must be accomplished to maximize cooperative interaction between modalities [73]." Holman gives an example of how vision dominates hearing for moving objects on a movie screen, calling it the "exit sign effect":
Under the pans, especially of fast moving objects, that break the left or right boundaries of the screen make the effect seem as though it continues the path off the screen that the visual image would take even though acoustically there is no way for this to occur. It seems that visual localization dominates aural localization in the case of localization confusion, especially in the transient case, such as these moving pans. Probably a more technically correct name for this effect is "perceptual overshoot dominance by vision over sound [66]."
While video images were not presented to listeners in this project, these effects are worth noting if one wants to generalize the results to audio-video systems.
General. Image azimuths near speaker locations may be pulled towards the speakers (the detent effect) because the listeners can see the speakers (especially L, C, and R). Gerzon’s energy vector direction, supposedly corresponding to higher frequencies, also predicts that higher frequencies (700 Hz - 3.5 kHz) will be pulled towards the speaker locations for the constant power and hybrid laws, and much less so for the optimal algorithm. (The energy vector direction for the Moorer algorithm was too erratic to predict if the detent effect would occur.) The detent effect in fact was observed for most algorithms. (For instance, note that the phantom images at 36° and 72° in the stationary panning plots are almost always above and below the ideal localization angles, respectively -- always towards L.)
Sounds panned between the L and SL speakers (or R and SR) are expected to show more localization errors than those panned between the front speakers [75]. Theile and Plenge [75] found that the perceived image azimuth was a steeper function of level difference between a pair of speakers at 60° and 120° (at the side) than for a pair of speakers at 30° and 330° (in the front). (Recall that our L and SL speakers are located at 45° and 120 ° , respectively.) This problem should show up in the constant power and hybrid algorithms at 90° and 270° as "holes" in the stationary pan test sections and as "accelerations" in the moving pan sections. It turned out that there was not enough azimuthal resolution in either set of sections to determine whether these deficiencies were present. (Theile and Plenge typically had resolutions of about 8° between each image their subjects were trying to localize.) One of the recommendations in Chapter 6 is to conduct another study much like theirs.
Constant power. Based on its energy vector direction plots, this algorithm should show poor localization in the statically panned test sections. Specifically, there should be wrongly perceived azimuths or large standard deviations seen at 25% and 75% of the angle between each adjacent pair of loudspeakers (if the chosen test azimuths fall on these angles). For the same reason, it should show poor consistency of speed in the moving pan sections. For off-center listening, this algorithm should show the worst azimuth distortions directly in the middle of adjacent speakers where 1 - rE is greatest. The moving head sections should show the good agreement with the fixed head sections because rV is always below unity. The constant power algorithm should show distance consistency in the moving pan sections because of the nature of the algorithm.
Moorer. Because it was not possible to plot the Moorer algorithm’s energy vector, localization performance can not be predicted based on the agreement of the velocity and energy vectors. Then again, the suppression of the 2nd order spatial harmonics in this algorithm was supposed to have ensured that the sound field was not warped (and thus localization good). The high number of speaker channels "sounding" for any given angle is expected to produce a wide stereo image and hence large standard deviations in the static panned tests. It is unknown how the spikes in an otherwise perfect rV plot should affect the moving head sections. Based on 1 - rE, the Moorer algorithm should perform very badly in the off-center tests. The speed, distance, and image width should have poor scores for the moving tests, especially between the rear speakers where the total power is almost triple that of constant power.
Hybrid. There should be a discontinuity in the localization of statically panned sounds near the L and R speakers, where the hybrid algorithm changes from optimal to constant power. Otherwise, it should behave as the optimal algorithm in the front sound stage and constant power in the rear sound stage.
Optimal. The optimal algorithm should show slight inconsistency in distance in the moving pan sections because it only approximates constant power behavior. Based on its velocity and energy vector plots, the optimal algorithm should show very smooth and predictable localizations, especially between the L, C, and R speakers. However, it may exhibit some poor localization performance just to the rear of both the L and R speakers where the velocity and energy vectors differ the greatest. Recall that to develop the optimal 5-channel pan pot, Gerzon’s original 3-channel optimal pan pot and a 4-channel version were piecewise spliced together at the L and R speaker locations. The value for rV just exceeds unity around these two speaker locations, possibly predicting poor motional head performance. Based on 1 - rE, the optimal algorithm should perform well for sounds panned in the front sound stage, but fair to poorly in the rear sound stage, in the off-center tests.
At first, listeners did not feel they had enough time to write down answers for all of the test sections. However, over time they got into the rhythm of listening to the noise bursts, looking down, writing their answers, and looking up again. The ADAT tape did have to be stopped during all sections to allow the listener time to flip pages of the questionnaire. There was not enough time to respond to the moving pan questions, so the ADAT tape was stopped between each moving pan until the listener was ready to move on. (The time spent considering each of the moving pan questions seemed to make each successive one harder to answer because the auditory event was harder to remember.)
The 0.7 s noise bursts for the static pan sections may have been too short in duration for exploratory head movements to do much good. In other words, by the time subjects were done turning their heads the sound was over. This may account for the fact that some listeners did not move their heads that often when they were given the option in sections 2 and 5.
Listeners had great difficulty in identifying the locations of some of the panned sounds. In the stationary panning sections, auditory events sometimes were localized as diagonal splits or even "everywhere." Answers to some questions may have been affected as a result of listeners taking too much time on the preceding question if it was hard to localize. For this reason, listeners were allowed to write a "?" for sounds they had great trouble localizing.
The noise burst that was supposed to accompany the last moving pan question (both sections) was missing on the ADAT tape. This corresponded to the constant power algorithm moving through region 4 (270 - 0 degrees counter-clockwise). After the test, this last noise burst was discovered to have been deleted accidentally in Deck while assembling audio files for the ADAT tape.
The listeners reported the following observations during breaks. Various listeners thought there were anywhere from three to twelve algorithms being tested. In the moving pan tests, listeners heard sounds going around them (as expected), past them as if a rocket shot straight through the speaker circle, around them in a semicircle and then straight up, or a sequence of moving toward them, enveloping ("morphing around") them, and moving past them. All of these creative perceptions were attributed to the Moorer algorithm in regions 1 or 4.
Breaks between test sections were sometimes less than the desired 2 minute duration but always greater than 1 minute.
Entering the moving pan answers into Matlab was a straightforward process. For the stationary pan answers, however, angle measurements had to be made for each test question. Recall that each of the four stationary pan sections (1, 2, 4, and 5) included forty circles upon which the listener indicated their perceived azimuth. These forty questions (circles) were divided such that there were ten questions (circles) per page. To aid in their measurement, a transparency was created that could be laid over each group of ten answers. Ten circles with radial lines drawn every five degrees were placed on the transparency to correspond with those on the questionnaire page. Measurements could be made much more quickly in this way than with a protractor.
The listeners’ pen marks were sometimes as wide as 10° , and the author used his best judgment accordingly. The measurements were entered into Matlab with an estimated accuracy of ± 1° . A Matlab procedure was created to flag any measurements that were more than 25° from the desired angle. All flagged measurements then were remeasured to decrease the likelihood of measurement or data entry errors.
Once listener answers had been entered into Matlab, they could be analyzed statistically. Answers to the stationary and moving pan sections were treated differently. The moving pan scores were normalized to 5 (out of 10) as follows. All of the moving pan scores for each listener were averaged, and the difference between their mean score and 5 was subtracted from all of their scores. The sample means and standard deviations for all eleven listeners were computed normally using each listener’s recentered data.
Statistical computations must be altered for the stationary pan sections because the true mean of 359° and 1° is 0° and not 180° . Gerzon addressed the problem of calculating statistical measures for data on a circle, and his equations were used for mean azimuth and circular standard deviation [76]. For perceived azimuths q 1, q 2, … , q n, we can form the following sums:
(4.8)
,
(4.9)
where the sample size n = 11. Then we can write Eqs. (8) and (9) in polar coordinates as
(4.10)
,
(4.11)
where 0 £ r £ 1, and 0° £ ![]() £ 360° . Finally, we can solve for r and
£ 360° . Finally, we can solve for r and ![]() as:
as:
(4.12)
(4.13)
(We are only interested in ![]() .) The mean azimuth
.) The mean azimuth ![]() finally was processed with an unwrapping algorithm that is necessary because of properties of the inverse
tangent. The circular standard deviation s is computed as follows:
finally was processed with an unwrapping algorithm that is necessary because of properties of the inverse
tangent. The circular standard deviation s is computed as follows:
(4.14)
where we must limit r to 0 < r < 1 so that s is real and finite.
This is said to reduce to the usual equation for data with a small angular scatter [76]. Note that "?" answers could not be used in the computation of ![]() and s
. However, each "?" answer may be interpreted as likely increasing the standard deviation had they been answered. Question marks were displayed next to
their respective mean azimuths in all plots.
and s
. However, each "?" answer may be interpreted as likely increasing the standard deviation had they been answered. Question marks were displayed next to
their respective mean azimuths in all plots.
While the above measures are useful, they do not tell the entire story. If we are to make statistical inferences from the data, the effects of sample size must be taken
into account. Inferences must be made knowing the confidence interval that is inversely proportional to the sample size n. In our case, the confidence interval is
measured in degrees azimuth. An example inference would be "with 95% confidence, we can say that a similar group of listeners under similar conditions would
localize this sound at 36° ± 7.6° ." Here the mean azimuth ![]() is 36° and the confidence half-interval h is 7.6° .
is 36° and the confidence half-interval h is 7.6° .
For the case of a small sample size and a two-sided statistical test, the confidence half-interval h can be computed as
,
(4.15)
where critical value t = 2.228 for 95% confidence, and t = 1.812 for 90% confidence [77]. Mean azimuths were plotted with 95% confidence intervals for the stationary panning sections (1, 2, 4, and 5). Mean scores for consistency in speed, distance, and image width were plotted with 90% confidence intervals for the moving pan sections (3 and 6). (Note that a two-sided test is necessary when deviations on either side of the hypothetical value would tend to discredit the hypothesis [77]. Here, the hypothesis is that the azimuths will lay on the ideal localization curves described below.)
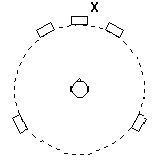
Localization azimuths should equal the desired ones for the center listening position, so ideal localizations fall along a straight line. We do not expect the same results for off-center listening. Assuming that sounds will still be localized around the loudspeaker circle, we can find the expected azimuths by doing a two-foot translation of axes to the right. Figure 4.8 shows this axis translation.
![]()
Fig. 4.8. Localization for sound source X is changed if one moves from
(a) the center listening position to (b) an off-center position.
This translation process is described as follows. Compute the x- and y-components for each azimuth measured from the center listening position. (In our coordinate system, the x-axis points forward towards 0° azimuth and the y-axis points left towards 90° azimuth.) Translate each pair of components into the (u, v) coordinate system using u = x and v = y + 2, where "2" is our two foot offset to the right. Finally, compute the new azimuth and radius using q = unwrap (atan(v/u)) and r = sqrt (u^2+ v^2), respectively. Figure 4.9 shows ideal localization azimuths for the ten azimuths used in this experiment.

Fig. 4.9. Ideal localization azimuths for center and off-center seating.
Speakers are located 6 ft from the center seat. Off-center listening is 2 ft to the right of center.
A rough approximation to the best-case half-interval h was computed based on the worst-case localization blur of 2.8º for narrow-band noise bursts at an azimuth of 0º (from Stiller (1960), referenced by [14]). Recall that localization blur is the amount of displacement of the position of the sound source that is recognized by 50% of listeners. If we map this blur for 50% of the subjects to the interquartile range, and if we assume a normal distribution and a mean that equals the median, we can translate the 2.8º localization blur to a value of standard deviation (Eq 4.16). (Blauert also assumes that a normal distribution is reasonable.)
(4.16)
This gives a half-interval h of 2.56º for the 95% case using Eq. (4.15). While localization blur (and hence h) does vary with azimuth and signal, this rough value of h was plotted as a constant to be a best possible case for localization blur for a similar signal. (If desired, this process could be reversed so that localization blurs for each of the mean azimuths could be plotted instead of the confidence intervals.)
Caveat. A comment about pan pot usage is relevant to analyzing the results of the listening test. Engineers mix by ear when working on a recording. When an engineer wants to pan a sound, he or she grabs a pan pot and turns it until the phantom image appears at the desired azimuth. As long as the image is localized easily (with low localization blur), the engineer does not care if a slight difference exists between the knob’s angle and localization azimuth of the image [38]. However, if this error varies greatly as the pan pot is turned, the "feel" of the pan pot would be hard to learn. In this case, the panning algorithm may not have great application for moving pan effects (for which the pan pot must respond smoothly).
(Previous Chapter) <- Main Page -> (Next Chapter)
Jim West, University of Miami, Copyright 1998